








 Промо акции
Промо акции Сервисные контакты
Сервисные контакты Поддержка
Поддержка Демо-стенды
Демо-стенды Статусы и сертификаты
Статусы и сертификаты Выполненные проекты
Выполненные проекты 
 8 (495) 411-82-82
8 (495) 411-82-82-
8 (800) 500-82-81
 cbs@cbs.ru
cbs@cbs.ru Пн-Пт с 10:00 до 18:30
Пн-Пт с 10:00 до 18:30 109544, г. Москва, ул. Малая Андроньевская, 20/8, стр. 1-1А
109544, г. Москва, ул. Малая Андроньевская, 20/8, стр. 1-1А
Управление сетью передачи данных
- 25.09.2014
- 9268
Автор
Сергей Калашников, CCIE
Технический директор
Статья опубликована в сентябрьском и октябрьском номерах «Журнал сетевых решений/LAN».
Оглавление- Введение
- Обеспечение доступа к сетевым устройствам для управления ими
- Мониторинг сетевой инфраструктуры
- Документирование сетевой инфраструктуры
- Комплексные системы мониторинга сетевой инфраструктуры
- Заключение
Введение
Задача управления компьютерной сетью является неотъемлемой, а во многих случаях и главной обязанностью сетевого инженера или администратора. На первый взгляд, что сложного в работе сетевого инженера? С точки зрения рядовых сотрудников компании, сетевой инженер получает сообщения от пользователей сети о тех или иных неисправностях (например, не работает Интернет, не подключается телефон к сети, «тормозит» RDP) и проводит работы по устранению данных неисправностей. Такие работы могут быть охарактеризованы как реактивная поддержка.
К сожалению, для обслуживания крупной сети реактивный подход во многих случаях недостаточен. В какой-то момент времени количество сообщений о неисправностях начнёт увеличиваться лавинообразно, что может привести к отказу критичных сетевых сервисов. В настоящее время практически для любого предприятия компьютерная сеть является бизнес-критичным инструментом. Даже пятиминутный простой сети может привести к значительным убыткам, поэтому перед сетевым инженером ставится задача избежать подобных ситуаций.
Для предотвращения непредвиденного отказа сети инженер должен применять комплексный и структурированный подход к задаче управления сетью, включающий, в том числе, выполнение проактивных действий.
Итак, в общем случае, задача управления компьютерной сетью может быть разделены на две составляющие:
- Структурированные работы – запланированные работы по поддержке сети;
- Реактивные работы – работы по устранению выявленных неполадок;
Безусловно, в реальной сетевой инфраструктуре свести к нулю реактивные работы не представляется возможным, однако, структурированный подход при управлении сетью позволяет минимизировать такие работы. Кроме того, структурированный подход позволяет более эффективно выявлять и устранять уязвимости в компьютерных сетях.
Существуют определённые модели (ITIL, FCAPS, TMN, Cisco Lifecycle Services), описывающие задачу поддержки IT-инфраструктуры в целом или сетевой инфраструктуры в частности. Рекомендуется использовать такие модели как отправные точки при разработке структурированной схемы управления компьютерной сетью. Наш опыт показывает, что процедуры, описанные в стандартизованных моделях во многих случаях избыточны. В данной статье попробуем обозначить наиболее важные, на наш взгляд, средства и инструменты управления, использование которых будет гарантировать надёжную и предсказуемую работы компьютерной сети.
Итак, выделим основные пункты, которые требуется выполнять в рамках решения задачи управления сетью и попробуем разобраться, какую роль в управлении сети играет каждый из предложенных пунктов.
- Обеспечение доступа к сетевым устройствам для управления ими. Безусловно, сетевой инженер должен иметь возможность в любой момент времени подключиться к сетевому устройству, чтобы внести изменения в настройки или посмотреть телеметрическую информацию. Основной инструмент управления сетевым устройством - командная строка (CLI), однако, практически все современные сетевые устройства предоставляют удобный графический интерфейс (GUI).
Существует широкий спектр программного обеспечения, с помощью которого можно одновременно управлять сразу несколькими устройствами и/или технологиями.
Следует отметить, доступ к сетевым устройствам необходим не только для сетевого инженера, но и для системы мониторинга. Кроме того, при решении задачи обеспечения доступа к сетевым устройствам крайне важно соблюдать надлежащий уровень безопасности.
Задача обеспечения доступа к сетевым устройствам не тривиальна, особенно для больших территориально распределённых сетевых инфраструктур. Управление может быть организованно по тем же каналам связи, где передаётся пользовательский трафик, по выделенным каналам или из облака. - Мониторинг сетевой инфраструктуры. Данный пункт наиболее интересен в рамках предложенной статьи, затрагивает достаточно объёмную задачу. Мониторинг сетевой инфраструктуры предлагаем разбить на следующие компоненты:
- Мониторинг сетевых устройств;
- Мониторинг каналов передачи данных.
- сбор системных сообщений – логов устройства;
- мониторинг доступности и телеметрии сетевого устройства;
- оповещение инженера об изменениях в сети;
Опыт наших инженеров показывает, что мониторинг в рамках описанных выше задач является необходимым и достаточным для поддержания работы сетевой инфраструктуры на надлежащем уровне. При аккуратном соблюдении предложенных (и, в общем-то, не сложных) пунктов, сетевой инженер сможет справиться практически с любой сетевой проблемой в сжатые сроки. Многие сетевые неполадки могут быть устранены проактивно.
Если учтены не все предложенные пункты, сетевой инженер в какой-либо момент времени обязательно столкнётся с ситуацией нехватки информации для решения очередной проблемы. Придётся экстренно добавлять недостающие средства мониторинга, а это увеличивает время решения проблемы. Кроме того, даже после установки нового инструмента мониторинга, сетевой инженер не всегда сможет достоверно интерпретировать новые данные, ведь у него нет информации о том, как сеть работала раньше, какие показатели считать нормальными, а какие аномальными. - Замена устаревшего или вышедшего из строя оборудования. С течением времени надёжность сетевых устройств падает. Устаревшее оборудование подвержено новым видам атак, поэтому представляет уязвимость для сетевой инфраструктуры в целом. Кроме того, устаревшее оборудование с определённого момента времени перестаёт отвечать постоянно возрастающим требованиям по функциональности производительности. Таким образом, сетевой инженер должен иметь исчерпывающую информацию о моделях используемых сетевых устройств и проводить замену оборудования на более современные устройства при необходимости.
- Обновление программного обеспечения сетевых устройств. Производители сетевого оборудования постоянно разрабатывают новые операционные системы для устройств. Как правило, выход новой версии программного обеспечения обусловлен исправлением уязвимостей операционной системы, исправлением ошибок (багов) в коде, увеличением производительности, а также добавлением нового функционала.
- Резервное копирование конфигураций сетевых устройств. При отказе устройства с наибольшей долей вероятности теряется его конфигурация. Сетевой инженер должен заменить вышедшее из строя устройство аналогичным, имеющим такие же настройки. Безусловно, задача замены отказавшего устройства значительно упрощается и ускоряется, если сетевой инженер имеет резервную копию конфигурации.
Ещё один пример, сетевой инженер вносит изменения в конфигурации сетевого устройства. После внесения изменений перестаёт работать часть сервисов (возможно, бизнес-критичных). Такая ситуация может произойти как по вине сетевого инженера (человеческий фактор), так и по вине производителя программного обеспечения (проявляется баг). Тем не менее, работоспособность сервиса должна быть восстановлена в сжатые сроки. При наличии резервной копии рабочей конфигурации сетевой инженер может быстро провести процедуру отката. - Поддержка документации сетевой инфраструктуры. Как правило, первоначальная документация сетевой инфраструктуры создаётся на этапах проектирования и внедрения. Однако в процессе эксплуатации вносятся многочисленные изменения в настройки сетевых устройств, в топологию сети и т.д.
В дальнейших разделах данной статьи мы постараемся разобрать наиболее интересные моменты из предложенных пунктов более подробно и попробуем привести пример, как те или иные инструменты помогают решать вопросы управления.
Обеспечение доступа к сетевым устройствам для управления ими
При организации управления сетевыми устройствами необходимо выбрать тип построения схемы управления, а также обеспечить правильную и безопасную настройку самих устройств для обеспечения подключения к ним с целью настройки.
Классические типы управления
На данный момент можно выделить несколько типов управления сетевым оборудованием. К наиболее часто описываемым методам относятся управление внутри полосы передачи трафика (in-band) и вне полосы передачи трафика (out-of-band). Кроме классического подхода существует несколько альтернативных вариантов управления сетевым оборудованием. Например, на рынке существует сегмент готовых решений, где управление устройствами происходит из облака. Конечно же его можно было бы отнести к одному из ранее описываемых, но в силу его некой гибридности и специфики мы хотели бы его выделить в отдельный класс. Также не стоит забывать, что сейчас огромную популярность набирает концепция SDN (программно-конфигурируемые сети). Итак, давайте разберёмся, что представляет каждый тип.
Первый тип управления in-band предполагает передачу трафика управления оборудованием (Telnet, SSH, HTTPs и пр.) и трафика мониторинга (Syslog, SNMP, Netflow и пр.) по тем же физическим каналам и портам на сетевом оборудовании, где передаётся и обычный пользовательский трафик. Т.е. одна и та же сеть обеспечивает передачу всех данных. Безусловно при настройке оборудования необходимо на логическом уровне сегментировать трафик управления и остальной трафик. Это можно сделать, используя виртуальные сети (VLAN), списки доступа (ACL), межсетевые экраны и прочее. Но, как было отмечено ранее, «физика» остаётся одной. Основной полюс такого решения – простота. Но за простоту, как это обычно бывает, приходится платить. Основной минус данной схемы заключается в том, что при неработоспособности сети (например, из-за большого паразитного трафика) у нас может пропасть доступ к сетевым устройствам для управления. Это затруднит диагностику и исправление ситуации в работе сети. Чтобы этого не произошло, необходимо на сетевом оборудовании настроить разные уровни качества обслуживания трафика (QoS). Для трафика управления и мониторинга потребуется выделить минимально необходимую полосу пропускания, с приоритетом, позволяющим его передавать, даже если сеть перегружена, предварительно его промаркировав. Однако такой подход не даёт 100% гарантии и усложняет настройку оборудования. Также есть вероятность, что устройство по какой-то причине автоматически заблокирует порт, и удалённый доступ к нему пропадёт (например, коммутатор Сisco может перевести порт в состояние err-disabled). Также можно просто по ошибке заблокировать порт, через который идёт трафик управления, тем самым потеряв доступ на само устройство.
Второй тип управления out-of-band предполагает передачу трафика управления по отдельным физическим каналам связи. Т.е. строится вторая сеть, которая обслуживает передачу трафика управления. На каждом сетевом устройстве выделяет отдельный порт для подключения к этой сети. Обычно используется выделенный коммутатор, к которому подключается вся инфраструктура управления (машина администратора, Syslog-сервер, Netflow-коллектор и прочее). При такой организации, администратор сети практически всегда будет иметь доступ на сетевое оборудование, даже если основная сеть полностью отказала. Безусловно основными минусами являются необходимость использования отдельного оборудования, а также дополнительных настроек. Ещё стоит обратить внимание, что при организации out-of-band управления всегда требуются отдельные каналы связи. Когда оборудование стоит в одной серверной, это не является большой проблемой. Всегда можно найти дополнительные патч-корды. Но если оборудование разнесено по зданию или находится на территориально распределённых площадках, вопрос с выделенными каналами становиться критичным. Как это часто бывает, дополнительные медные или оптические трассы проложить достаточно проблематично, если они не были изначально предусмотрены. Также стоит обратить внимание на необходимость наличия на сетевом оборудовании дополнительных портов для подключения к сети управления. Очень часто в маршрутизаторах присутствует всего два физических интерфейса, которые обычно уже заняты.
В случае если у нас территориально распределённая сеть, организовать управление out-of-band в удалённом офисе, особенно, если его топология достаточно проста, становится сложным и не оправданным с точки зрения цены. Поэтому появляется гибридный вариант управлению сетью: out-of-band для центрального офиса и in-band для удалённых офисов. Точно такая же схема может быть использована, если наша сеть распределена по зданию и в силу отсутствия дополнительных межэтажных соединений, организовать везде out-of-band управление с становится сложно.
Хотелось бы отметить ещё один вариант управления сетью, который в большей степени можно отнести к out-of-band – использование консольного сервера. В этом случае каждое сетевое устройство подключается к консольному серверу, через который происходит управление оборудованием. Большое преимущество данного варианта управления в том, что консольный доступ позволяет подключиться к устройству, даже если устройство не смогло корректно загрузится. Но у этого варианта есть несколько нюансов, которые не всегда позволяют использовать только такой вариант управления. Забегая вперёд, хотелось бы отметить, что консольный сервер может и должен использоваться как дополнительный элемент в in-band или out-of-band схемах управления. Основные ограничения заключаются в том, что к консольному серверу удобно подключать те устройства, которые находятся на небольшом удалении, т.е. в одной серверной комнате. Также консольное подключение нельзя использовать в качестве решения по мониторингу сетевого оборудования. Ещё один нюанс связан со скоростью передачи данных через консольное подключение. Вывод большого количества информации может занять достаточно продолжительное время. На нашей практике были случаи вывода информации в течение 30 минут.
Помимо консольного сервера, как альтернативный вариант, можно иметь специально выделенный ноутбук с консольным кабелем. Т.е. минимальный комплект, позволяющий подключиться к сетевому оборудованию по консоли. Такой вариант позволит при необходимости достаточно оперативно дойти до устройства и подключится к нему. Обычно в нужный момент, нет или ноутбука под рукой или консольного кабеля с переходником.
Альтернативные типы управления
Как уже говорилось, управление из облака является в некотором роде гибридным типом. Одним из примеров управления сетевым оборудование из облака, является концепция, реализованная в линейке продуктов Cisco Meraki. Все устройства этой марки (а туда входят и коммутаторы, и устройства безопасности, а также решения по построению беспроводной сети) автоматически после установки подключаются в облако Cisco. Далее для их управления сетевой инженер подключается к облачному порталу. Главным недостатком данной схемы является тот факт, что если пропадает связь с облаком, управлять устройствами не получится. Это существенно повышает требования к надёжности и количеству Интернет-каналов. Стоит отметить, что такой тип управления ещё не набрал популярности. Но в свете облачного тренда, видимо, мы туда дошагаем достаточно быстро.
Концепция программно-конфигурируемых сетей является одной из наиболее развивающихся на рынке сетевых технологий. Она предполагает полное отделение функций управления устройствами и контроля трафика от функций передачи данных. То есть за управление всеми сетевыми устройствами и логику контроля за трафиком (например, протоколы маршрутизации, служебные протоколы, vlan) отвечает некое централизованное программное устройство (контроллер), а сетевые устройства занимаются только передачей трафика. С одной стороны, плюсы подхода налицо: это удобное управление всей сетью, с очень гибким функционалом (дополнительные функции реализуются программно). Однако, сейчас только начинают появляться сетевые устройства с поддержкой данной технологии и функционал их пока крайне ограничен, перспективность такого подхода будет определена в ближайшие годы.
Корректная и безопасная настройка сетевого оборудования для управления
В идеале настройка сетевого оборудования для обеспечения функций управления и мониторинга должна советовать рекомендация производителя оборудования. Пароли должны иметь достаточную степень надёжности. Для удалённого подключения должны такие протоколы как, SSH и HTTPs. Доступ к устройству должен быть ограничен. Список таких рекомендаций можно продолжать достаточно долго. При этом есть ещё рекомендации по корректной настойке каждого протокола управления, рекомендации по настройке качества обслуживания (QoS), рекомендации по снятию телеметрии с оборудования и т.д. Если открыть рекомендации по настройке всех этих параметров, увидим, что они занимают не одну страницу, и их пересказ вряд ли будет интересен. Поэтому давайте зададимся вопросом, а на сколько всё это нужно? Любой специалист конечно же ответит: «Да, безусловно нужно». Поэтому правильнее сформулировать вопрос по-другому. Где та золотая середина между достаточным уровнем безопасной управляемости устройствами и нужной глубиной мониторинга и сложностью настройки сетевого оборудования? Ведь, наверное, нет смысла настраивать весь спектр функции при любом удобном случае. Лично мы так не делам. Безусловно не стоит впадать и в ту крайность, когда на оборудовании даже не меняются логин с паролем, установленные по умолчанию. При этом доступ к таком устройству открыт из любой точки сети. Должен быть некий компромисс, так сказать достаточное необходимое.
Думаю, каждый для себя определяет этот минимум из его жизненного опыта. Кто-то перестаёт оставлять открытыми все порты, после того, как взламывают его оборудование. Кто-то начинает везде включать логирование, только после того как оборудование внезапно отказало, и понять причину из-за отсутствия лог-сообщений не удалось. В связи с этим хотелось бы в общих чертах описать те моменты в плане настройки управления, которые на наш взгляд необходимы.
Приведём краткий перечень рекомендаций, который можно расширить или дополнить, обратившись к документации на оборудование:
- Для удалённого подключения рекомендуем использовать только защищённые протоколы, такие как, SSH и HTTPs. Для тренировки можно попробовать провести захват трафика подключения по протоколу telnet. В этом трафике вы без труда найдёте логин с паролем, передаваемые в открытом виду.
- На всех устройствах должны быть настроены логины и пароли с достаточной степенью надёжности. Все учётные записи по умолчанию следует удалить. Все пароли должны храниться в конфигурации в защищённом виде.
- Весь трафик мониторинга и управления, передаваемый по открытым каналам должен быть зашифрован: либо с помощью vpn соединения, либо с использованием защищенных протоколов (snmpv3, sftp, scp).
- Доступ к устройству должен быть ограничен только для определённого круга пользователей. Например, на оборудовании Cisco это можно сделать с помощью списков доступа (ACL).
- На устройствах должна быть настроена синхронизация времени. Это позволит более точно определять монеты, когда производилась попытка легитимного или не легитимного подключения.
- Все подключения и вводимые команды рекомендуется логировать. Особенно это актуально в случае управления устройством несколькими людьми.
- Каждый пользователь должен подключаться, используя свою уникальную учётную запись.
Кроме того при необходимости разные пользователи могут иметь разный уровень доступа на устройство. При подключении должно выводиться сообщение о том, что доступ разрешён только авторизованным пользователям.
Как было отмечено ранее, кроме рекомендаций, касающихся непосредственного управления устройствами, существуют такие же рекомендации по безопасной настройке различных протоколов (например, EIGRP, OSPF и пр.), обеспечивающих работу сети. Например, рекомендуется всегда включать логирование изменений состояния протокола (добавление/удаление маршрутов и пр.), а также аутентификацию между устройствами при установление соседственных отношений.
Также есть целый набор рекомендаций по настройке качества обслуживания (QoS) трафика управления и мониторинга. Туда же можно отнести вопросы фильтрации и ограничения скорости для того или иного протокола с целью предотвращения атаки типа «отказ в обслуживании».
Мониторинг сетевой инфраструктуры
Мониторинг сетевых устройств включает в себя сбор системных сообщений, мониторинг доступности и телеметрии сетевого устройства, а также оповещение инженера об изменениях в сети. В качестве системных сообщений на многих устройствах, в том числе устройствах Cisco, служат syslog сообщения. Сбор телеметрических данных производится с использованием протокола SNMP. Для оповещения инженера об изменениях в сети, на сетевом оборудовании должны быть настроены средства посылки уведомлений. Мониторинг каналов связи организуется по средствам протокола Netflow или его аналогов. Далее каждый этап будет рассмотрен более подробно.
Syslog сообщения и их анализ
Логи визуализируют процесс работы сетевого устройства, отображают его состояние. Выполнение системой какого-либо действия отражается соответствующим системным сообщением – логом. Существуют различные уровни детализации системных сообщений. Как правило, в зависимости от уровня детализации информации в логах на оборудовании существуют различные уровни логирования. Для оборудования Cisco Systems представлены 8 уровней: от уровня 0 (Emergencies – сообщения о неработоспособности системы) до уровня 7 (Debugging – отладочные сообщения).
Оборудование Сisco Systems предоставляет следующие возможности по выводу логов: на консоль устройства (console logging), в локальный буфер устройства (buffer logging), в терминальную линию (monitor logging) и на внешний сетевой накопитель – выделенный Syslog-сервер. В роли последнего может выступать централизованная система мониторинга.
При включении логирования нужно быть крайне внимательным. Существуют некоторые нюансы, невыполнение которых может привести к отказу устройства и/или необходимости его перезапуска.
Первый нюанс касается вывода в консоль или на терминальную линию логов высокого уровня детализации, в частности – уровень 7. Особенно данный пункт касается ситуации, при которых инженер активирует дополнительную трассировку какого-либо сервиса командой debug. Сетевое устройство может генерировать слишком большое количество сообщений в единицу времени, всё процессорное время будет затрачено на вывод данных сообщений на экран. Устройство может «зависнуть» и перестать выполнять свою главную функцию – маршрутизировать и коммутировать сетевой трафик. При необходимости просмотра логов высокого уровня детализации рекомендуем выводить сообщения в локальный буфер.
Второй нюанс касается вывода лог-сообщений в локальный буфер. На сетевых устройствах Cisco локальный буфер выделяется из общего пула оперативной памяти. Если мы запросим слишком большой объём памяти под лог-буффер, устройству может испытывать нехватку оперативной памяти, что в свою очередь, может привести к «зависанию» устройства, незапланированной перезагрузке. Отдельно стоит выделить настройку логирования на межсетевых экранах Cisco ASA. Распределение лог-сообщений по уровням для многих случаев не является оптимальным. Например, сообщения, связанные с работой списков доступа (ACL) на устройстве или с правилами трансляции IP-адресов (NAT) могут иметь уровни от 2 до 6. Например, при попадании трафика под действие списка доступа может генерироваться сообщение:
Error Message %ASA-2-106006: Deny inbound UDP from outside_address/outside_port to inside_address/inside_port on interface interface_name.
Таким образом, даже при нормальном режиме работы устройства постоянно могут появляться лог сообщения высокого уровня критчности. В связи с этим операционная система межсетевого экрана Cisco ASA предоставляет сетевым администраторам широкие возможности по настройке и оптимизации логирования на устройстве. Инженер имеет возможность изменить уровень для любого лог-сообщения. Кроме того, администратор может создавать списки системных сообщений, объединяя в группы интересующие события. Например, для отладки и мониторинга работы сервиса VPN, сетевой инженер может создать список, в который будут попадать только лог-сообщения, связанные с работой данного сервиса, и отправлять на выделенный Syslog-сервер только настроенный список. Кроме того, устройство Cisco ASA может отправлять списки лог-сообщений по электронной почте. Для любого сетевого устройства системные лог-сообщения являются главным, а в некоторых случаях и единственно доступным инструментом поиска проблем и неисправностей. При проведении диагностики сетевой проблемы, инженер, после проверки корректности конфигурации, первым шагом должен посмотреть логи сетевых устройств. Вероятность выявления причины проблемы по системному логу крайне велика.
Системные сообщения незаменимы при расследовании сетевых проблем, моменты проявления которых непредсказуемы. Приведём простой пример такой ситуации. Сетевой администратор получает периодически от пользователей жалобы о том, что три-четыре раза за рабочий день пропадает связь центрального офиса с удалённым. Что делать в такой ситуации?
Уточним у пользователей, в какие моменты времени пропадает связь и посмотрим логи сетевых устройств в интересующий временной интервал. Предположим, по логам видно, что на всём сетевом оборудовании центрального офиса пропадает маршрут в удалённый офис. Смотрим логи оборудования удалённого офиса. Замечаем, что как раз в интересующие нас интервалы времени на маршрутизаторе, к которому подключен канал до центрального офиса, появлялось критическое сообщение о нехватке оперативной памяти на устройстве и последующая перезагрузка.
Таким образом, по лог-сообщениям мы смогли локализовать проблему и понять причину её появления.
Помимо решения сетевых проблем, хотелось бы отметить ещё одну область применения системных сообщений. Лог-сообщения можно использовать совместно со встроенным в операционную систему устройств Cisco редактором автоматических сценариев Cisco EEM (Embedded Event Manager). Данный функционал позволяет создавать скрипты для автоматического изменения конфигураций устройств. Лог-сообщение может выступать триггером запуска скрипта.
Сбор данных по протоколу SNMP
Протокол SNMP – Network Management Protocol – является стандартом для обмена управляющей информацией между сетевыми устройствами и системой управления сетью (NMS – Network Management System). С точки зрения мониторинга сети протокол SNMP является незаменимым средством сбора телеметрической информации с сетевых устройств.
Сбор телеметрических показателей сетевых устройства является неотъемлемым компонентом управления компьютерной сетью. Телеметрическая информация позволяет сетевому инженеру искать «узкие места» в сетевой топологии, предотвращать возможные отказы, отслеживать причины сетевых проблем, определять рабочие уровни (baseline) для показетелей сетевых устройств, выявлять аномалии в работе сети.
К наиболее важным датчикам телеметрии устройств относятся такие показатели, как загрузка процессора устройства, загрузка оперативной памяти, работа систем питания, охлаждения, температура устройства.
Перечисленные показатели телеметрии рекомендуется отслеживать на любом сетевом устройстве. Кроме того, на устройствах, в зависимости от возложенного функционала, рекомендуется включать мониторинг дополнительных параметров. Так, для устройств, терминирующих VPN-подключения, рекомендуется опрашивать соответствующие SNMP OID. Для многих сетевых устройств важно знать текущую загрузку сетевых интерфейсов. Данная информация поможет достаточно точно оценить загрузку каналов передачи данных в сетевой инфраструктуре. Пример графика загрузки процессора коммутатора Cisco, полученный благодаря опросу устройства по SNMP, представлен на рисунке 1. Пример графика загрузки сетевого интерфейса коммутатора Cisco представлен на рисунке 2. Существует ряд сетевых проблем, поиск причин и устранение которых неосуществимы без наличия информации по телеметрии сетевых устройств, собранной по протоколу SNMP. К таким проблемам относятся ситуации, при которых связь пропадает не полностью, но качество связи ухудшается, становится неприемлемым для определённых сетевых приложений. В большинстве случаев при возникновении подобных проблем сетевой инженер не может получить практически никакой информации посредством проверки конфигураций сетевых устройств или просмотром лог-сообщений. В результате таких первичных проверок создаётся впечатление, что вся сетевая инфраструктура работает корректно и безотказно. Но при этом постоянно поступают жалобы от конечных пользователей о том, что «видео не грузится», «телефония работает плохо и качество голоса неприемлемо».
Наиболее вероятной причиной возникновения подобных проблем является возросшая нагрузка на сетевые устройства и/или на каналы передачи данных. С помощью NMS, собирающего телеметрию сетевых устройств по SNMP, легко оценить динамику изменения нагрузки на сетевые устройства. Вполне вероятно, что на пути следования проблемного потока данных, находятся одно или несколько сетевых устройств, загруженных сверх меры. После обнаружения таких устройств инженер сможет сделать вывод о том, являются ли данные узлы «узким местом» сетевой топологии, либо данные устройства подвержены какому-то аномальному нежелательному влиянию (вирусная активность, нелегитимный трафик больших объёмов и т.д.). Если устройство оказалось «узким местом», сетевой инженер должен поднять вопрос о замене оборудования на более производительную модель. Если высокая загрузка является аномалией – требуется дальнейшее расследование.
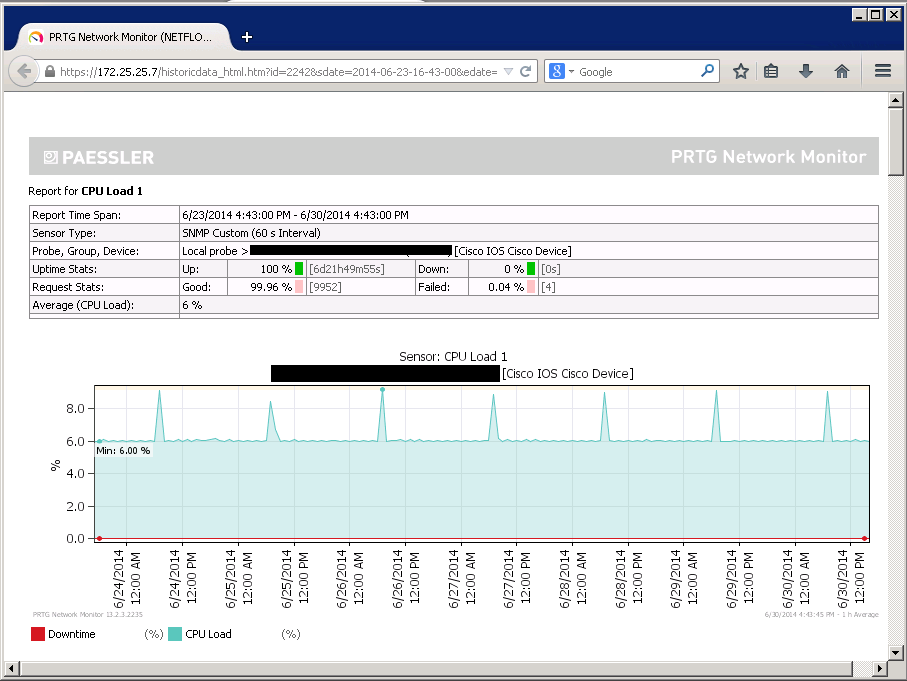
Рисунок 1. График загрузки процессора коммутатора Cisco
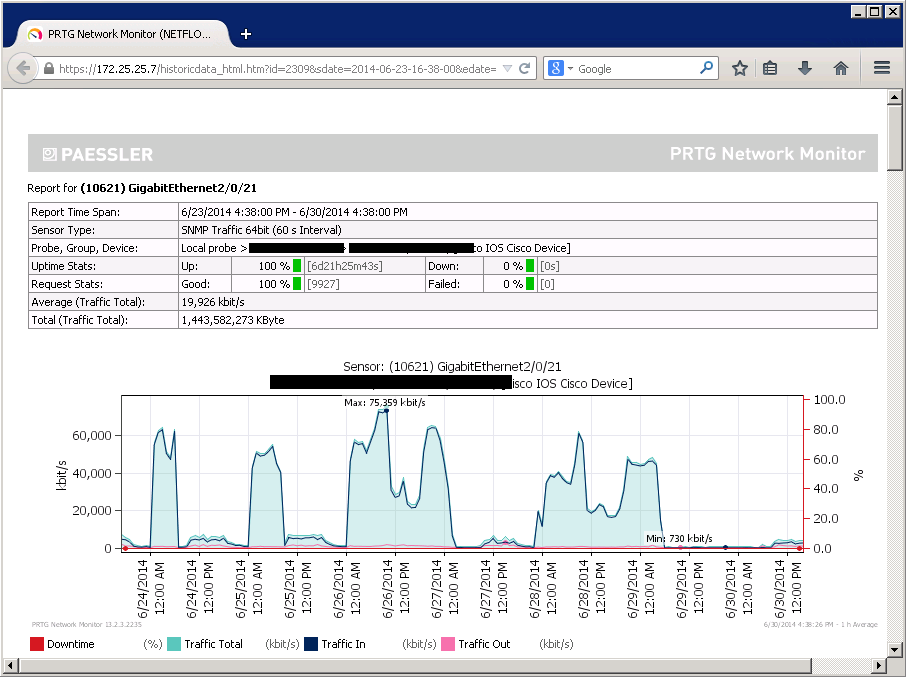
Рисунок 2. График загрузки сетевого интерфейса коммутатора Cisco
Например, с помощью данных, полученных по SNMP, мы можем локализовать «паразитный трафик», загружающий сетевое оборудование. Средствами SNMP можно опрашивать OID устройств, отвечающих за загрузку сетевых интерфейсов. Если «перегруженным» устройством является коммутатор, велика вероятность, что на паре его интерфейсов мы сможем увидеть аномально высокий уровень загрузки. Во многих случаях подобные рассуждения актуальны и для маршрутизаторов. После выявления пары интерфейсов инженер может уточнить, какие устройства подключены к данным портам. Возможно, для подтверждения выдвинутой гипотезы также отключить эти интерфейсы на время и посмотреть, снизится ли загрузка сетевого устройства и улучшится ли в конечном итоге качество связи. Таким образом, сбор информации по SNMP помогает выявить причину проблемы, расследовать которую другими средствами не представляется возможным.
Необходимо отметить, проблема с ухудшением качества связи может проявляться не только вследствие сверхмерной загрузки сетевого оборудования, но и в результате высокого уровня утилизации каналов связи. Опять же, опрос по SNMP OID устройства, содержащего информацию о загрузке сетевых интерфейсов, помогает выявить и косвенно определить загрузки подключенных к интерфейсам каналов. Опишем простейший пример. К интерфейсу высокопроизводительного маршрутизатора Cisco подключен WAN-канал. Пропускная способность канала по договору с провайдером составляет 10 Мбит/с. Пользователи, опять же, периодически испытывают проблемы с качеством связи по этому каналу. С помощью сбора информации по SNMP мы определили, что на протяжении всего времени использования канала загрузка интерфейса маршрутизатора, к которому канал подключен, не превышала 3 Мбит/с. Однако с некоторого момента времени наблюдается загрузка 10-12 Мбит/с, что превышает пропускную способность канала. Конечно, производительность подавляющего большинства моделей маршрутизаторов Cisco позволяет «прокачивать» трафик в 10-12 Мбит/с. Очевидно, проблема в чрезмерном уровне утилизации WAN-канала. В данной ситуации дальнейшее расследование проблемы средствами SNMP затруднительно: нужно определить качественный состав трафика в канале, то есть IP-адреса отправителей/получателей протоколы и используемые порты. Описанная задача решается с помощью протокола NetFlow. Более подробно данный протокол будет рассмотрен в разделе «Сбор данных по протоколу NetFlow».
Сбор данных по протоколу NetFlow
Протокол NetFlow разработан компанией Cisco Systems. С точки зрения проблемы управления сетью данный протокол является незаменимым инструментом для мониторинга загрузки каналов передачи данных.
Конечно, протокол NetFlow не может получать информацию непосредственно с канала (витой пары или оптической линии) – данные снимаются с устройств, подключенных непосредственно к интересующему сегменту. NetFlow поддерживается многими сетевыми устройствами. По NetFlow могут отправлять информацию маршрутизаторы, коммутаторы и межсетевые экраны Cisco. NetFlow является проприетарным протоколом Cisco Systems, однако, следует отметить, существует и открытый аналог данного протокола – sFlow. SFlow реализован в современных моделях сетевых устройств многих производителей сетевого оборудования – HP, Zyxel и т.д.
Архитектура NetFlow крайне проста и состоит из двух компонентов: сетевое устройство, отправляющее информацию о проходящем через него трафике, и NetFlow-коллектор. Последний является сборщиком и анализатором информации, полученной по NetFlow.
Принцип действия протокола заключается в следующем. На сетевом оборудовании при открытии очередной сессии передачи данных формируется информация о данной сессии, называемая поток (flow). Поток содержит в себе такую информацию, как количество передаваемых байт, входной и выходной интерфейс для сессии, IP-адреса источника/приёмника, порты источника/приёмника, номер протокола IP, параметры QoS и т.д. Потоки аккумулируются на сетевом устройстве и отправляются в сторону NetFlow-коллектора в UDP-датаграммах. NetFlow-коллектор агрегирует полученную информацию, проводит анализ и формирует удобные отчёты и графики. Один из популярных NetFlow-коллекторов – NetFlow Analyzer, но существуют коллекторы и других производителей. С помощью протокола NetFlow сетевой инженер получает полную картину трафика на каналах. Инженер может просматривать качественный состав трафика (IP-адреса, порты, приложения) в любом сегменте сети, а также оценивать, какой процент пропускной способности канала занимает тот или иной поток.
Основные области применения NetFlow: мониторинг утилизации каналов передачи данных, учёт трафика, проведение аудитов сетевой инфраструктуры. Задача учёта трафика ставится в основном для компаний-провайдеров связи. При проведении аудита, NetFlow помогает собирать детальную информацию о реальном передаваемом в сети трафике.
Для того чтобы понять, каким образом NetFlow может помогать сетевому инженеру в процессе управления сетью, вернёмся к рассмотрению примера с периодически ухудшающимся качеством связи (вопрос был затронут в разделе «Сбор данный по протоколу SNMP»). Итак, мы имеем следующие входные данные. От пользователей периодически поступают жалобы о том, что «сеть тормозит и телефония глючит». С помощью протокола SNMP мы определили, что загрузка всех сетевых устройств на маршруте следования трафика находится в допустимых пределах. Однако на устройстве, к которому подключен канал WAN, предоставляемый провайдером, загрузка интерфейсов необычно высока для данного участка. По счётчикам интерфейсов, видим, что количество переданного/принятого трафика канала равно и превышает предоставляемую провайдером полосу пропускания.
В данной ситуации протокол NetFlow поможет инженеру визуализировать картину, что конкретно происходит в проблемном канале. Инженер может увидеть, какое приложение чрезмерно утилизирует канал и, главное, между какими парами IP-адресов происходит передача данных. Вполне вероятно, что по IP-адресам инженер может сразу узнать конечных пользователей, генерирующих трафик. Далее, дело остаётся за малым. Инженер может уточнить у пользователя, насколько важно для него используемое приложение. Если острая необходимость в данном сервисе отсутствует, сетевой инженер может запретить подобный трафик с помощью списка доступа на сетевом оборудовании для предотвращения повторных проявлений проблемы. Если же пользователь говорит о том, что данный сервис критичен для бизнеса в целом, сетевой инженер должен поднимать вопрос о расширении полосы пропускания канала или приобретении новых дополнительных каналов. На время решения данного вопроса сетевой инженер, как правило, может настроить политики QoS таким образом, чтобы трафик проблемного приложения не занимал всю полосу пропускания, оставляя достаточно ресурсов для передачи как минимум голосового трафика.
Стоит отметить, сбор информации по протоколу NetFlow вносит дополнительную нагрузку на сетевое оборудование, поэтому, не стоит снимать данные по NetFlow со всех узлов сетевой инфраструктуры. Рекомендуется снимать информацию по NetFlow на сегментах сети, для которых эта информация действительно необходима. К таким участкам в первую очередь относятся точки подключения внешних линий связи: выделенных линий, WAN-каналов, предоставляемых провайдерами, каналов для подключения к сети Интернет.
Уведомления
Все существующие комплексные системы мониторинга сетевых устройств позволяют настраивать уведомления о событиях на устройствах. Уведомления можно отправлять в качестве SNMP trap или syslog сообщений, email сообщений, через sms шлюз. Важно настроить корреляцию сообщений и отправлять именно критичные сообщения, на которые необходимо оперативно отреагировать. Также важно распределить группы ответственности (тип оборудования, уровень ошибок, расположение и т.п.) и отправлять информацию только необходимой группе администраторов.
Даже если у вас нет выделенного сервера с системой мониторинга, способной по определенным событиям (syslog, SNMP) отправлять сообщения на электронную почту, вы можете сделать это средствами маршрутизатора. В маршрутизаторах Cisco функционал Embedded Event Manager (EEM) позволяет отправить сообщение email по указанному событию. Триггером может служить, например, syslog сообщение о том, что не доступен трек ip sla. Иными словами, при отказе основного провайдера и переключении на резервный канал, вам на почту придет письмо с сообщением об этом. Это очень удобно для небольших сетей.
Документирование сетевой инфраструктуры
Хорошая документация залог того, что если в сети что-то сломается или необходимо будет внести в её работу какие-то изменения, все эти работы будут проведены вне зависимости от каких-то внешних условий. Многие компании пренебрегают документированием сети, до того момента пока не уволится сотрудник, обслуживающий данную сеть. Сделать документацию один раз не так, оказывается, сложно, нежели поддерживать её в актуальном состоянии. При этом создание документации и поддержание её актуального состояния по большому счёту ручной труд, который лишь частично может быть автоматизирован.
Глубина проработки документации может варьироваться как от степени сложности самой сети, так и от того, на кого она ориентирована. Например, для сложных топологий сети должен обязательно существовать план по восстановлению работоспособности в случае серьёзного сбоя. Если в компании есть дежурные администраторы, для них могут быть подготовлены инструкции по решению каких-то типовых проблем или задач. В состав документации, на наш взгляд, обязательно должны входить следующие разделы: доступ на оборудование (логины, пароли, интерфейсы управления на оборудовании, ограничения по доступу), физическая топология сети, логическая топология сети, краткое описание работы основных узлов. Вся документация должна храниться в защищённом месте, так как она является ключом ко всей сети.
Одной из важных задач документирования является составление актуальной топологии сети. Собрать информацию о топологии сети можно как вручную, так и с использованием автоматизированных средств. В обоих случаях состав средств, используемых для сбора информации примерно одинаков.
Где же брать информацию о текущей топологии? Сбор информации о физической топологии сети путем осмотра и инвентаризации непосредственно на месте мы не берем, тут всё довольно очевидно. К тому же, часто этот путь затруднителен, трудоемок и вносит дополнительные риски, ведь для проверки некоторых каналов, вероятно, потребуется их отключение. Все ли продолжит работать как прежде после такой инвентаризации? Кроме того, помимо физической топологии, необходимо внести информацию о соединениях и протоколах на канальном и сетевом уровнях. Для этого можно использовать как специализированные протоколы (CDP, LLDP), позволяющие получить информацию о соседних устройствах, так и общепринятые служебные протоколы\таблицы, которые позволят получить необходимую информацию. Наиболее полезными являются: таблицы маршрутизации (соседние маршрутизаторы\коммутаторы, движение трафика), таблица MAC адресов (соседние устройства), STP (состояние портов), VTP (VLAN), ICMP и ARP (доступность устройства).
Визуализировать топологию можно также вручную, в одном из специализированных пакетов (MS Visio, ). Однако, в данном случае, невозможно оперативно отслеживать изменения в сети: любое изменение необходимо вносить вручную. Особенно сложно отслеживать изменения при большом количестве оборудования в сети и отсутствии жестких регламентов и требований к внесению изменений в конфигурацию оборудования и документацию.
Автоматическое (полностью или частично) составление топологии сети, как правило, входит в функционал системы мониторинга. Конечно, данный метод требует соответствующей подготовки сетевого оборудования для корректного сбора информации и составления топологии, однако он позволяет связать с топологией все функции системы мониторинга. Это и отображение состояния соединений в режиме онлайн, и состояние устройств и их доступность, текущие ошибки на устройствах и другие.
Отдельное внимание стоит уделить топологии беспроводной сети. Для оперативного мониторинга беспроводной сети на предприятии важно составить её топологию с расположением точек доступа на плане. Также не менее важна карта покрытия сети. С помощью системы мониторинга вы сможете видеть «стандартные» параметры для устройства (клиенты, диапазон, ошибки), а также, при необходимости, сможете отслеживать положение устройств. Можно осуществлять мониторинг не только легитимных клиентов сети - беспроводных клиентов, RFID-меток и других беспроводных устройств, но и в том числе устройств, создающих помехи в работе сети, а также угрозы в безопасности.
Комплексные системы мониторинга сетевой инфраструктуры
На сегодняшний день список систем мониторинга сетевых устройств огромен. Однако, действительно комплексных систем мониторинга сетевых устройств не так много. Такие системы имеют обширный функционал по мониторингу, настройке сетевых устройств, а также аудиту всей сети. Они способны собирать и анализировать множество протоколов (SNMP, syslog, NetFlow, CDP и др.) и предоставлять детальную информацию о работе сети. Из наиболее распространенных можно выделить продукты компаний SolarWinds, ManageEngine, Paessler, Cisco. Стоит также отметить такие продукты с открытым кодом, как Nagios и Zabbix. Система Nagios является стандартом мониторинга промышленной IT-инфраструктуры среди открытых систем, предоставляет огромный спектр функций по мониторингу сетевого оборудования. Недостаток системы – настройка мониторинга производится в ручном режиме, либо требует установки дополнительных графических интерфейсов. Отличительной особенностью системы Zabbix, по сравнения с Nagios, является наличие удобного графического интерфейса сразу «из коробки».
Как компания-партнер Cisco, чаще всего мы имеем дело с оборудованием именно этого производителя, поэтому в качестве примера использования хотели бы привести систему Cisco Prime Infrastructure (PI). PI является комплексной системой мониторинга с множеством функций, однако их описание достойно отдельной статьи. В данной статье мы бы хотели просто привести несколько ситуаций, где система мониторинга пригодилась нашим специалистам, на примере Cisco Prime. Вероятно, указанное в той или иной мере актуально и для других систем мониторинга.
Ситуация 1. Заказчик настроил новый функционал на маршрутизаторе. Всё работает, однако возникли проблемы с работавшими ранее сервисами.
Решение. Полный архив конфигурации для всех устройств позволил показать изменение в конфигурации устройства за последние три дня. Была найдена и исправлена ошибка в конфигурации.
Ситуация 2. Наблюдается нестабильная работа протокола DMVPN в одном из филиалов компании. Офис новый. Конфигурация типовая, развернута с помощью системы шаблонов на Prime.
Решение. При инвентаризации устройства и сравнении с остальными, выявлено, что установлена не стабильная версия ПО. Запланировано автоматическое обновление в нерабочее время.
Ситуация 3. Клиент с радиотелефоном жалуется на периодические проблемы «со связью», но на момент обращения все работает хорошо.
Решение. Отчет об уровне сигнала в течение дня показал, что действительно наблюдаются зоны резкого ухудшения сигнала. Выявляем проблемные участки, проводим дополнительный мониторинг работы БЛВС не дожидаясь повторного появления проблемы.
Ситуация 4. Сотрудник принес 3g устройство и раздает wifi без ограничений. Чтобы не вызывать подозрений раздает корпоративный SSID.
Решение. Система анализа «посторонних» устройств в беспроводной сети обнаружила угрозу по сигнатуре типа «использует наш SSID», уведомление отправлено администратору. С помощью топологии сети с позиционированием устройств определено примерное местоположение нелегитимной точки доступа. Точка локализована и выключена.
Ситуация 5. Удаленный сотрудник подключился по VPN и скачивает большие объемы данных из корпоративной сети, создавая нагрузку на маршрутизатор (шифрование, трафик).
Решение. Отчет по протоколу NetFlow обнаружил резкое увеличение трафика с одного из серверов корпоративной сети на хост в удаленной сети по протоколу smb/cifs. Настроено ограничение полосы пропускания.
Мы привели несколько простых примеров использования системы мониторинга в сети и как её функционал может существенно сократить время решения проблемы и предотвратить их появление. Конечно, такая система, скорее всего, не будет целесообразна, если у вас 10 устройств в сети. Однако, при достаточно объемной сети (в т.ч. распределенной) это крайне важный продукт, способный существенно уменьшить расходы на обслуживание сети и качество её работы.
По опыту ещё хотелось бы добавить, что одним из самых распространенных заблуждений является подмена понятий в упрощении обслуживания при использовании системы и простоты самой системы. Иными словами, часто, устанавливая систему, заказчик думает, что уже сам факт установки и подключения устройств к системе снимает большинство проблем и вопросов. Как правило, комплексная система — это сложный механизм, требующий тонкой настройки и совершенно не отменяющий наличия навыков по настройке и пониманию всего цикла работы оборудования у обслуживающих её (систему) специалистов.
Заключение
В данной статье мы попробовали раскрыть понятие «управление сетью», определить, какие задачи приходится решать сетевым инженерам для поддержания работоспособности сетевой инфраструктуры на надлежащем уровне, а также привести примеры проблем и варианты их устранения из реальной практики наших инженеров.
Основная идея нашей статьи достаточно простая. Заключается она в следующем: для эффективного управления сетью требуется не только реактивный подход к решению текущих задач и проблем, но и набор проактивных действий. Мониторинг сетевой инфраструктуры является главной проактивной задачей.
Основная задача мониторинга сети – собирать необходимую и достаточную информацию о работе сетевой инфраструктуры. В статье мы поделились с читателем опытом инженеров нашей компании на предмет, какие же средства обеспечивают ту самую «необходимость и достаточность».
Опыт наших инженеров показывает, что выполнение перечисленных в статье пунктов мониторинга позволяет сетевому инженеру иметь в любой момент времени достаточно информации для решения практически любой сетевой проблемы или задачи. При этом, невыполнение того или иного процесса мониторинга, как правило, приводит к нехватке данных для поиска причины и устранения сетевой проблемы.
Задача организации корректного отказоустойчивого и безопасного доступа к сетевым устройствам для их управления и мониторинга, а также задача документирования сети также не были оставлены без внимания в данной статье. Мы поделились своим взглядом на проблему решения этих задач.
В конце статьи мы кратко описали существующие системы мониторинга и привели примеры из реальной практики, как данные системы помогают решать различные сетевые задачи и проблемы. Надеемся, что в этой статье мы смогли убедить всех читателей в необходимости решения каждого из рассмотренных пунктов задачи управления сетью. Так что, если у Вас всё ещё нет Syslog-сервера в сети, или не настроен мониторинг по SNMP – мы идём к Вам!